Cowboy is a lightweight HTTP server with support for HTTP/1.1, HTTP/2 and Websocket.
It is built on top of Ranch. Please see the Ranch guide for more information about how the network connections are handled.
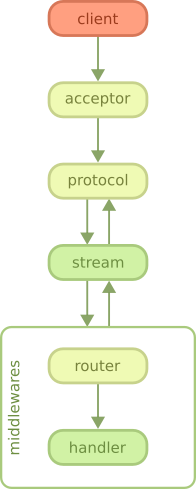
As you can see on the diagram, the client begins by connecting to the server. This step is handled by a Ranch acceptor, which is a process dedicated to accepting new connections.
After Ranch accepts a new connection, whether it is an HTTP/1.1 or HTTP/2 connection, Cowboy starts receiving requests and handling them.
In HTTP/1.1 all requests come sequentially. In HTTP/2 the requests may arrive and be processed concurrently.
When a request comes in, Cowboy creates a stream, which is a set of request/response and all the events associated with them. The protocol code in Cowboy defers the handling of these streams to stream handler modules. When you configure Cowboy you may define one or more module that will receive all events associated with a stream, including the request, response, bodies, Erlang messages and more.
By default, Cowboy comes configured with a stream handler called cowboy_stream_h. This stream handler will create a new process for every request coming in, and then communicate with this process to read the body or send a response back. The request process executes middlewares. By default, the request process executes the router and then the handlers. Like stream handlers, middlewares may also be customized.
A response may be sent at almost any point in this diagram. If the response must be sent before the stream is initialized (because an error occurred early, for example) then stream handlers receive a special event indicating this error.
Cowboy takes care of protocol-specific headers and prevents you from sending them manually. For HTTP/1.1 this includes the transfer-encoding and connection headers. For HTTP/2 this includes the colon headers like :status.
Cowboy will also remove protocol-specific headers from requests before passing them to stream handlers. Cowboy tries to hide the implementation details of all protocols as well as possible.
By default, Cowboy will use one process per connection, plus one process per set of request/response (called a stream, internally).
The reason it creates a new process for every request is due to the requirements of HTTP/2 where requests are executed concurrently and independently from the connection. The frames from the different requests end up interleaved on the single TCP connection.
The request processes are never reused. There is therefore no need to perform any cleanup after the response has been sent. The process will terminate and Erlang/OTP will reclaim all memory at once.
Cowboy ultimately does not require more than one process per connection. It is possible to interact with the connection directly from a stream handler, a low level interface to Cowboy. They are executed from within the connection process, and can handle the incoming requests and send responses. This is however not recommended in normal circumstances, as a stream handler taking too long to execute could have a negative impact on concurrent requests or the state of the connection itself.
Because querying for the current date and time can be expensive, Cowboy generates one Date header value every second, shares it to all other processes, which then simply copy it in the response. This allows compliance with HTTP/1.1 with no actual performance loss.
Cowboy makes extensive use of binaries.
Binaries are more efficient than lists for representing strings because they take less memory space. Processing performance can vary depending on the operation. Binaries are known for generally getting a great boost if the code is compiled natively. Please see the HiPE documentation for more details.
Binaries may end up being shared between processes. This can lead to some large memory usage when one process keeps the binary data around forever without freeing it. If you see some weird memory usage in your application, this might be the cause.
Donate to Loïc Hoguin because his work on Cowboy, Ranch, Gun and Erlang.mk is fantastic:
Recurring payment options are also available via GitHub Sponsors. These funds are used to cover the recurring expenses like food, dedicated servers or domain names.

